
Escalation Paths That Work: Faster Decisions, Fewer Fires
Why Escalation Paths Exist: The Real Job To Be Done
Escalation is a defined route for moving a problem or decision to the smallest group with the authority and context to resolve it within a set time. That is it. Not a CC-all. Not a panic button. A precision route with clear triggers, owners, and time limits.
Escalation paths serve three non-negotiable outcomes:
- Protect the customer and the business when time, risk, or impact exceed normal operations.
- Shorten decision latency by moving work to the right altitude fast.
- Create learning loops so the organisation gets stronger after every incident or block.
The Cost of Bad Escalation: Symptoms You Already See
Leaders often recognise the smoke but not the fire source. If any of these are familiar, your escalation path is broken:
- Ping-pong handoffs and “who owns this?” messages during urgent work.
- Over-escalation to the most senior person available because the path is unclear.
- Slack theatre: performative urgency, zero decisions, endless updates.
- Escalations weaponised as blame instead of a route to resolution.
- Late discovery of legal, compliance, or reputational risk because triggers are subjective.
- Executives dragged into triage, starved of time for strategy.
These are not people problems. They are design problems. Fix the path and behaviour follows.
What Good Looks Like: Seven Hard Rules
Your escalation path is an operating mechanism. Treat it like one.
- One owner at every level. A single directly responsible individual (DRI) for each stage. No committees. Named backups in writing.
- Objective triggers. Pre-agreed thresholds for impact, time, risk, or value that force escalation. No feelings. Clear numbers.
- Time-boxed stages. Every level has a maximum time to acknowledge and to resolve, after which automatic escalation occurs.
- One level at a time. Escalate to the next responsible level, not straight to the top. Skip-level only when triggers demand it.
- Decision rights are explicit. The receiver of the escalation knows what they can decide unilaterally.
- Single channel of record. One place for updates, decisions, and artefacts. Everything else is noise.
- Recovery and learning loops. After action reviews with fixes tracked to completion. The path evolves.
Design Escalation Across the 6Ps
Escalation sits inside your operating model. Consider it through PerformanceNinja’s big-picture lens:
- Purpose. Tie escalation goals to customer protection and strategic outcomes.
- People. Train roles, not just individuals. Build bench strength and backups.
- Proposition. Define severity by user impact and brand risk for each product.
- Process. Map flows, triggers, decision rights, and artefacts. Keep it simple.
- Productivity. Instrument with metrics and service levels. Shorten decision latency.
- Potential. Use learnings to improve design, quality, and innovation pipelines.
The Three Escalation Patterns Every Organisation Needs
Different problems need different routes. Do not force everything through one pipe. Build three paths and keep them tight.
1) Incident Escalation: When Something Breaks
Use this for outages, security events, major defects, supplier failures, or anything affecting customers or operations.
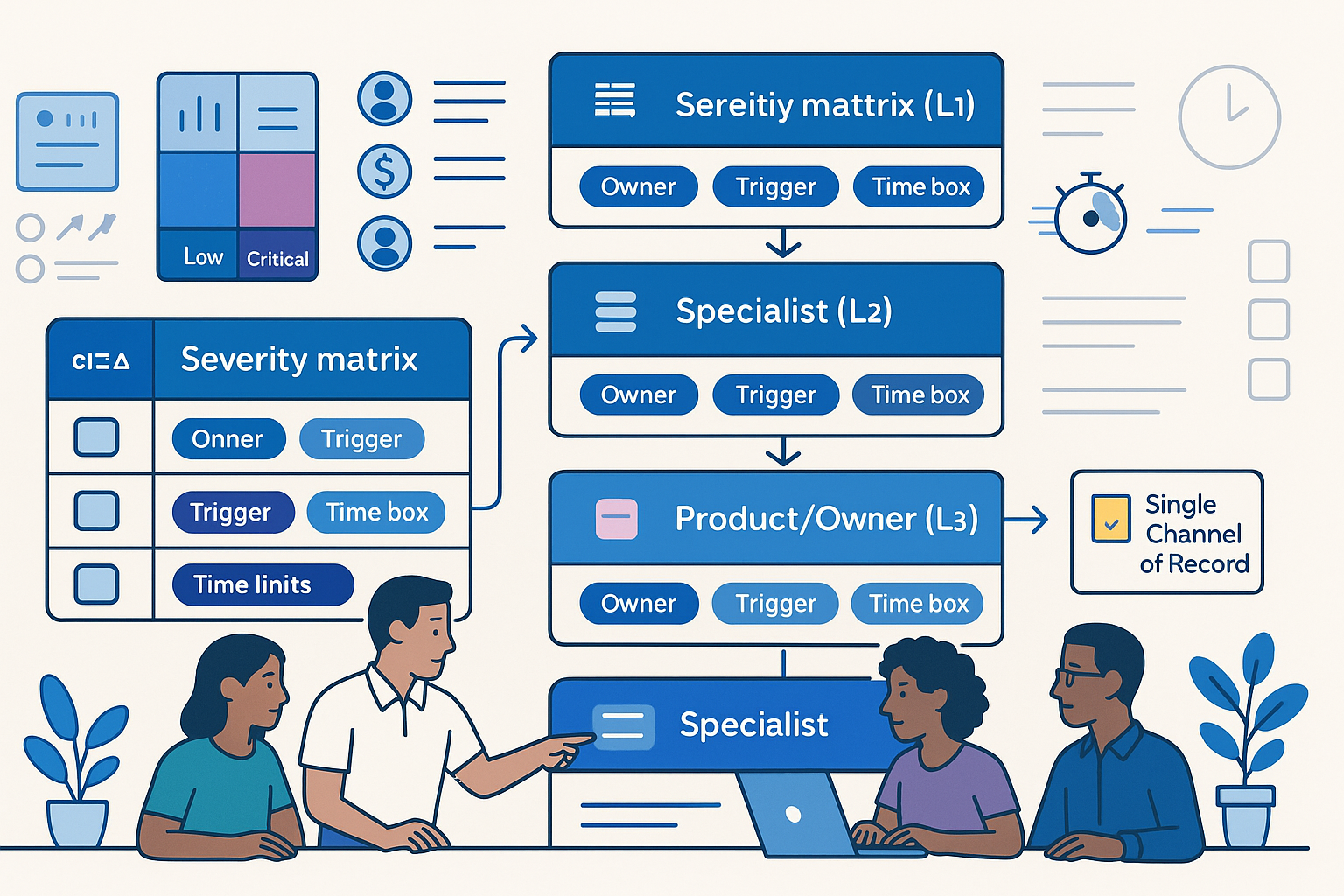
- Levels. L0 self-serve knowledge base and automated remediation. L1 frontline ops or support. L2 specialist engineer or resolver group. L3 product or platform owner. L4 executive duty officer for business risk and external comms.
- Roles. Incident Commander (one), Comms Lead, Technical Lead, Resolver Teams. No spectators.
- Triggers. Severity matrix combining user impact, financial exposure, legal/compliance risk, and time since detection. Predefined thresholds map to L1–L4.
- Time boxes. Acknowledge in 5 minutes at each level. Containment target within 30–60 minutes for high severity. Business decision within 120 minutes if risk persists.
- Channel. Dedicated incident channel with bot-generated header: context, timeline, owner, severity, decision log link.
- Comms. Templated stakeholder updates at set intervals until resolved. One voice.
2) Decision Escalation: When Work Is Blocked
Use this for cross-team dependencies, priority conflicts, funding decisions, or policy exceptions.
- Levels. Team lead, then function lead, then portfolio leadership, then exec sponsor.
- Triggers. Ageing blockers beyond X working days, value at risk above £Y, or strategic dependency at risk for launch date Z.
- Decision rights. Each level has a budget, scope, and policy override limit. Publish the table.
- Cadence. Weekly portfolio unblock session with a 24-hour fast track for high-value items.
- Artefact. One-page decision brief: context, options, trade-offs, recommendation, time needed, failure cost. No slide decks.
3) People Escalation: When Behaviour or Safety Is at Risk
Use this for conduct issues, harassment, safety concerns, or repeated performance breaches.
- Levels. Line manager, then HR business partner, then functional head, then People leader/Legal.
- Triggers. Breach of code of conduct, safety risk, legal risk, or repeated pattern after documented feedback.
- Guardrails. Confidentiality rules, documentation standards, and interview protocols to protect fairness and legal footing.
- Time boxes. Immediate acknowledgement within one business day. Investigation plan within three. Clear next steps within ten.
Set Triggers That Cannot Be Argued With
Subjective triggers create arguments, not action. Use hard thresholds. Adopt a simple severity model that anyone can apply in 30 seconds.
- Customer impact. Number of users affected and depth of impact: none, degraded, blocked.
- Financial risk. Revenue at risk per hour/day or total exposure estimate.
- Time risk. Countdown to breach of an external commitment or regulatory deadline.
- Legal/brand risk. Any data, privacy, safety, or reputation exposure triggers auto-escalation.
Define numeric bands and map them to levels. Publish the mapping. Example: “If >5 percent of active users are blocked for 15 minutes or more, raise to L3 within five minutes. If any personal data exposure is suspected, raise to L4 immediately.”
Time Boxes, Not Wishful Thinking
Speed is a design choice. Bake it into the path.
- MTTA targets. Mean time to acknowledge at each level within 5 minutes for incidents; within 24 hours for decision escalations.
- Containment targets. High severity incidents contained within 60 minutes. If not, auto-escalate and consider user-facing mitigations.
- Decision latency caps. Portfolio-level decisions in 48 hours. Executive calls in 72 hours unless legal or safety risk demands faster.
Make Decision Rights Explicit
Escalation fails when the receiver does not know what they can decide. Publish a decision rights table by level and path:
- Incident path. Technical Lead can roll back, failover, feature-flag off without additional approval up to agreed impact thresholds. Exec duty officer can pause campaigns or notify regulators.
- Decision path. Function lead can reassign up to 2 FTE for two weeks, trade scope within project boundaries, or approve spend up to £X. Portfolio can alter quarterly priorities within guardrails.
- People path. Line manager can issue written feedback, escalate to HR for investigation. People leader can apply interim measures to protect team safety.
One Channel of Record
Pick the channel and make it the truth. All updates and decisions live there. Link to tickets, runbooks, dashboards, and the decision log. Everything else is commentary.
For incidents, auto-create a digital room with a pinned header:
- Incident name, severity, owner, start time
- Current hypothesis and next step
- Decision log link and update cadence
- Stakeholder update owner and schedule
Escalation Message Template: Seven Lines That Cut Through
Use this structure for any escalation. It works because it forces clarity.
- Context. What changed and why it matters.
- Impact. Who is affected and how.
- Trigger. Which threshold was hit.
- Time. When this started and time remaining before worse outcomes.
- Options. Two to three viable options with trade-offs.
- Recommendation. Your proposed call and the smallest next step.
- Ask. What decision or action you need, by when, and from whom.
Tooling That Helps Without Owning You
Tools do not fix design, but good ones remove friction:
- Ticketing with mandatory fields for severity, owner, trigger, and time boxes.
- On-call schedules with named backups and escalation chains.
- Incident channel bots that create headers, reminders, and decision logs.
- Runbook libraries linked contextually in tickets and channels.
- Portfolio unblock boards for decision escalations with WIP limits.
Metrics That Matter
Measure the mechanism, not the noise:
- MTTA and MTTR. Mean time to acknowledge and to resolve by severity.
- Escalation rate. Percentage of work items requiring escalation by type.
- False escalation rate. Escalations that did not meet triggers.
- Reopen rate. Incidents reopened within 7 days. Signals premature closure.
- Decision latency. Time from escalate to decision for portfolio items.
- Learning velocity. Percentage of reviews with actions closed within 30 days.
Anti-Patterns To Eliminate Now
You will recognise these. Kill them with policy and practice.
- Escalate by volume. Adding more people to a problem creates delay and diffusion. Keep the room small.
- Escalate by title. The highest-paid person in the room is not the mechanism. Follow the path.
- Vague asks. “Flagging for visibility” is not an escalation. Ask for a decision.
- Infinite updates. Update cadence is fixed. Outside that, teams work.
- Blame hunts. Root cause is useful. Root blame is theatre and destroys learning.
Examples: What This Looks Like In Practice
Example 1: Major Customer Outage
Trigger: 8 percent of users cannot log in for 12 minutes. L2 engineer pages Incident Commander. Severity auto-set to High. Acknowledge in 3 minutes. Hypothesis: recent auth change. Action: feature-flag rollback by Technical Lead. Containment achieved at 28 minutes. Comms every 15 minutes to stakeholders. Post-incident, we add a canary check for auth and tighten change windows. Learning actions closed in 21 days.
Example 2: Priority Conflict Blocking Launch
Trigger: Critical dependency ageing beyond 5 working days and £250k value at risk. Team lead escalates to function lead with a one-page brief. Decision within 24 hours: reassign two engineers for ten days and drop non-critical feature. Launch remains on date. Portfolio reviews guardrails in the next weekly session.
Example 3: Conduct Concern
Trigger: Reported harassment aligned with code-of-conduct breach. Line manager escalates to HR within 24 hours. Investigation plan in three days. Interim measures implemented to protect the team. Clear comms on process and next steps. Confidentiality preserved. Follow-up closed in line with policy timelines.
Training and Drills: Make It Muscle Memory
Escalation paths work when they are used and practised. Run drills like any other critical system.
- Monthly mini-drills. 30-minute simulated incident with on-call, comms, and rollback.
- Quarterly game days. End-to-end scenario for a core product or process.
- Blameless reviews. Focus on mechanism failures and improvements, not individual fault.
- Role rotation. Build depth by rotating Incident Commander and Comms Lead roles.
Governance Without Bureaucracy
Keep the mechanism light but strong.
- Publish the escalation matrix, triggers, decision rights, and time boxes.
- Update quarterly or after any significant incident or organisational change.
- Ensure legal and security are embedded in triggers and playbooks, not copied in ad hoc.
- Retire steps that do not add speed or safety. Fewer steps, stronger rules.
Implementation Plan: 30–60–90 Days
Days 0–30: Build the Backbone
- Map your three paths: incident, decision, people. One-page per path.
- Define triggers and time boxes. Convert debates into numbers.
- Assign DRIs and backups by level. Publish the list.
- Create the seven-line escalation template and mandate its use.
- Set up the single channel of record for incidents and decision escalations.
Days 31–60: Instrument and Drill
- Configure tooling: tickets, bots, runbook links, on-call schedules.
- Run two live-fire drills and one portfolio unblock session.
- Start measuring MTTA, MTTR, decision latency, and false escalation rate.
- Tighten triggers and time boxes based on signal from drills.
Days 61–90: Integrate and Improve
- Embed the paths in onboarding and manager training.
- Run one cross-functional game day touching legal, comms, and execs.
- Launch a monthly learning review. Close actions within 30 days.
- Publish a simple scorecard. Celebrate speed and learning, not heroics.
FAQs Leaders Keep Asking
Should we ever escalate straight to the CEO?
Only if triggers demand it, such as legal exposure or existential customer risk. Otherwise, your path is broken or your leaders lack decision rights. Fix the path.
How do we prevent over-escalation?
Publish triggers, enforce the seven-line template, and measure false escalation rate. Coach offenders. If over-escalation persists, your thresholds are wrong or your teams lack confidence the mechanism will respond. Improve response times.
How do we escalate across functions without chaos?
Use the decision brief and pre-agreed decision rights. Limit the room. Assign a single Incident Commander or Decision Chair. Keep a single channel of record.
What about vendors and partners?
Add them to your matrix with their own SLAs and escalation contacts. Mirror your triggers and time boxes in contracts. Integrate their updates into your channel of record.
What if the issue is sensitive?
Use the people escalation path with confidentiality guardrails. Limit access. Keep a written log. Involve Legal early based on triggers, not fear.
Leadership’s Role: Make It Safe to Escalate, Hard to Ignore
Leaders set the tone. If you punish escalation, people will hide problems until they are unmanageable. If you reward heroics over mechanism, you will get more fires. Make the path the hero. Praise fast escalation when triggers are met. Ask “what did the mechanism miss?” after every event. Fund the fixes. Protect the time boxes. Model the behaviour by following the path yourself.
The Payoff: Fewer Surprises, Faster Progress, Stronger Teams
Escalation paths that work do three things at once. They protect the customer. They accelerate execution. They grow capability. That is the trifecta of performance.
This is not paperwork. It is organisational engineering. Build the mechanism. Drill it. Measure it. Improve it. In a year, you will wonder how you ever ran the business without it.
Next Steps
Want to learn more? Check out these articles:
Clear Interfaces Between Teams: Build Speed, Cut Waste
Operating Model Clarity: Turn Strategy Into Results Quickly
Reduce Bureaucracy While Scaling: Leader’s Guide to Speed
To find out how PerformanceNinja could help you, book a free strategy call or take a look at our Performance Intelligence Leadership Development Programme.



